Project Documentation AI Assistent - Intermediate Example with RAG Support
Project Documentation AI Assistent - Intermediate Example with RAG Support
This is an example of an AI app utilising RAG (Retrieval-Augmented Generation). RAG tools are a specialised type of function tools that enhance your LLM by integrating a vector database created from anything you choose to vectorise. In most cases this will be additional data from a knowledgebase or a database, in this case we're incorportating the SubQuery documentation website as our RAG data (where you're reading this right now).
note
This tool is already in use in production for SubQuery documentation. Be sure to explore it now by clicking the corresponding button in the lower-right corner.
You can follow along in the tutorial with the example code here.
Prerequisites
In order to run an AI App locally, you must have the following services installed:
- Docker: This tutorial will use Docker to run a local version of SubQuery's node.
- Deno: A recent version of Deno, the JS engine for the SubQuery AI App Framework.
You will also need access to either an Ollama or OpenAI inference endpoint:
- Ollama. An endpoint to an Ollama instance, this could be running on your local computer or a commercial endpoint online, or
- OpenAI. You will need a paid API Key.
1. Install the framework
Run the following command to install the SubQuery AI framework globally on your system:
deno install -g -f --allow-env --allow-net --allow-import --allow-read --allow-write --allow-ffi --allow-run --unstable-worker-options -n subql-ai jsr:@subql/ai-app-framework/cliThis will install the CLI and Runner. Make sure you follow the suggested instructions to add it to your path.
You can confirm installation by running subql-ai --help.
2. Create a New App
You can initialise a new app using subql-ai init. It will ask you to provide a name and either an OpenAI endpoint or an Ollama model to use.
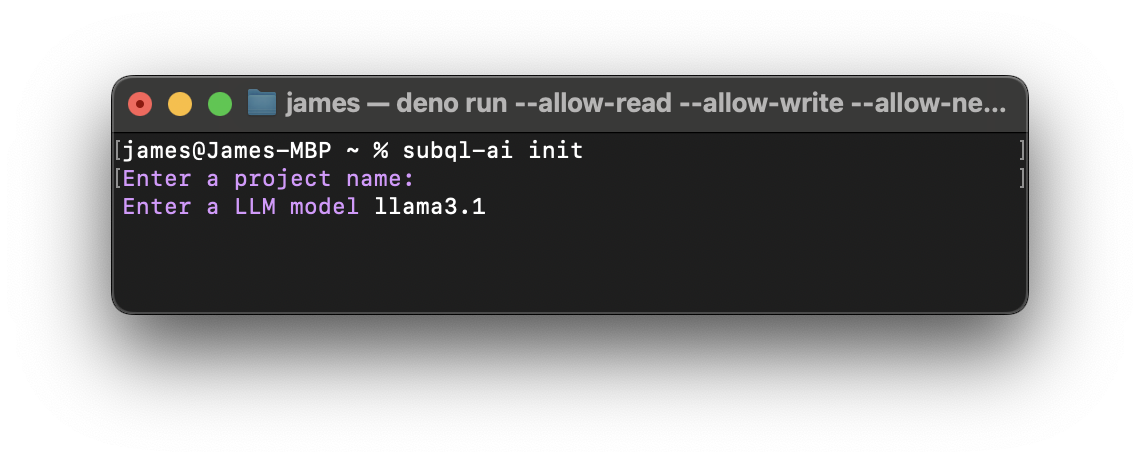
After you complete the initialisation process, you will see a folder with your project name created inside the directory. Please note that there should be three files, a project.ts, a manifest.ts, a docker-compose.yml, and a README.md.
3. Embedding Documentation for RAG
To proceed with our example, we need to define and add a RAG dataset. For this guide, we will experiment with the SubQuery documentation, but feel free to use your own markdown-based documentation, provided it can be vectorised.
Step 1: Clone the Documentation Repository
First, clone the SubQuery documentation repository by running the following command in your terminal:
git clone https://github.com/subquery/documentation.gitStep 2: Define the RAG Dataset
Once the documentation repository is cloned, you can define it using the SubQuery CLI. The default RAG tool can be utilised by following this guide. Here’s an example command:
subql-ai embed -i ./subquery/documentation -o ./db --table subql-docs --model nomic-embed-textHere’s a breakdown of the parameters used in this command:
-i(input): Specifies the path to the documentation repository you cloned, with no additional modifications required.-o(output): Indicates the path where the generated embeddings will be saved.--table: Defines the table name for storing the embeddings.--model: Specifies the embedding LLM model to use, which should match the model defined in the app's manifest.
Note
The logic for vectorisation is implemented in the SubQuery framework and can be found on GitHub.
The CLI processes markdown files within the specified directory and generates embeddings by performing the following steps:
- Splitting Markdown Files: Files are divided into sections based on headers.
- MDX Element Removal: Any MDX elements are stripped away.
- Plain Text Conversion: Each section's content is converted to plain text.
If the default vectorisation algorithm doesn’t suit your needs, you can use a custom algorithm tailored to your specific requirements.
Step 3: Review Generated Embeddings
After the vectorisation process is complete, a folder will be generated containing the embeddings. It will include subfolders and files similar to the structure shown below:
Copy the root path of this folder. You will need this path in the next step when configuring the manifest file to ingest and embed your chosen RAG source data.
4. Configure the Manifest File
The file manifest.ts defines key configuration options for your app. You can find the configuration specifics here.
Continue with the next steps to integrate the embeddings into your application. After the modification, the manifest file will resemble the following structure:
import type { ProjectManifest } from "jsr:@subql/ai-app-framework@^0.0.5";
const project: ProjectManifest = {
specVersion: "0.0.1",
vectorStorage: {
type: "lancedb",
path: "../path-to-previously-generated-db-folder",
},
config: {},
model: "llama3.1",
embeddingsModel: "nomic-embed-text",
entry: "./project.ts",
};
export default project;5. Configure App's Logic
To configure the app, you’ll need to edit the project entry point file (e.g., project.ts in this example). The project entry point is where the tools and system prompt are initialised.
A good first place to start is by updating your system prompts. System prompts are the basic way you customise the behaviour of your AI agent.
const PROMPT = `
You are designed to assist with answering questions about SubQuery, using its documentation as a reference.
You answer must use the result of the tools available.
Do not mention that you used a tool or the name of a tool.
If you need more information to answer the question, ask the user for more details.
`;Adding function tools is an important step of any integrated AI App. Function tools are functions that extend the functionality of the LLM. They can be used to do many things like request data from external APIs and services, perform computations or analyse structured data outputs from the AI. You can read more about function tooling here.
You can now add the tool to the array.
// deno-lint-ignore require-await
const entrypoint: ProjectEntry = async (): Promise<Project> => {
return {
tools: [new SubqueryDocs()],
systemPrompt: PROMPT,
};
};
export default entrypoint;After adding the tools to the array, you can begin implementing it. No explicit configuration is needed, as this is handled automatically by the SubQuery AI Framework SDK in the background.
export class SubqueryDocs extends RagTool {
constructor() {
super("subql-docs", "content");
}
}6. Run the AI App with developed tools
We can run the project at any time using the following command, where the -p is the path to the manifest.ts, and -h is the URL of the Ollama endpoint.
subql-ai -p ./manifest.ts -h http://host.docker.internal:11434Once the project is running you should see the following: Listening on http://0.0.0.0:7827/. You can now interact with your application. The easiest way to do that is to run the repl in another terminal.
subql-ai replThis will start a CLI chat. You can type /bye to exit. Alternatively, it is possible to launch the app via Docker.
You should review the instructions on running locally or via Docker.
Let's attempt to ask the tool specific questions:
How can I define a one-to-many relationship in a subquery project GraphQL schema?This should return a response that looks like the following:
Full Response
It seems like the SubQuery Docs API is still under development and doesn't support defining one-to-many relationships in GraphQL queries.
To answer your question, a one-to-many relationship can be achieved by using subqueries. Here's an example of how you could define a one-to-many relationship between two tables using a subquery:
type OneToOneExample {
id: ID!
anotherId: ID!
}
type Query {
oneToMany: [OneToOneExample!] @client
}
In this query, we have a `OneToOneExample` type that has two fields: `id` and `anotherId`. The `@client` keyword is used to indicate that the field is not a built-in GraphQL field.
The subquery is defined like so:
query MyQuery {
oneToMany: [one TO MANY ON ONE(id: $id, anotherId: $anotherId) FROM OneToOneExample!] WHERE $id IS NOT NULL AND $anotherId IS NOT NULL
}
In this query, we define a subquery that selects from the `OneToOneExample` type. The subquery is executed for each pair of distinct values in the `id` and `anotherId` fields. This will give us a list of records where one-to-many relationship between the two tables.
Please note that not all GraphQL databases support this syntax, so you may need to adjust it to fit your specific database schema.Another prompt:
Does subquery support the solana blockchain?Full Response
Subquery currently does not support Solana blockchain.Summary
You now have a fully functional SubQuery AI App that leverages unstructured markdown data to deliver clearer and more concise responses about SubQuery.
From here you may want to look at the following guides:
- Detailed documentation on the AI App Manifest.
- Enhance your AI App with function tooling.
- Give your AI App more knowledge with RAG support.
- API of AI App.
- Publish your AI App so it can run on the SubQuery Decentralised Network.