How does a SubQuery dictionary work?
How does a SubQuery dictionary work?
The whole idea of a generic dictionary project is to index all the data from a blockchain and record the events, extrinsics, and its types (module and method) in a database in order of block height. Another project can then query this network.dictionary endpoint instead of the default network.endpoint defined in the manifest file.
The network.dictionary endpoint is an optional parameter that if present, the SDK will automatically detect and use. network.endpoint is mandatory and will not compile if not present.
Taking the SubQuery dictionary project as an example, the schema file defines 3 entities; extrinsic, events, specVersion. These 3 entities contain 6, 4, and 2 fields respectively. When this project is run, these fields are reflected in the database tables.
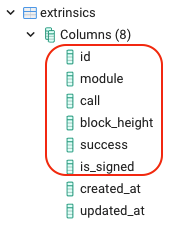
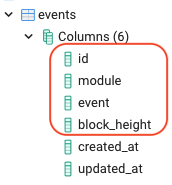
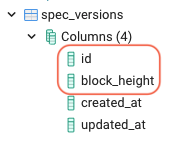
Data from the blockchain is then stored in these tables and indexed for performance.
How to incorporate a dictionary into your project?
Add dictionary: https://api.subquery.network/sq/subquery/dictionary-polkadot to the network section of the manifest. Eg:
network:
endpoint: wss://polkadot.api.onfinality.io/public-ws
dictionary: https://api.subquery.network/sq/subquery/dictionary-polkadotWhat happens when a dictionary IS NOT used?
When a dictionary is NOT used, an indexer will fetch every block data via the polkadot api according to the batch-size flag which is 100 by default, and place this in a buffer for processing. Later, the indexer takes all these blocks from the buffer and while processing the block data, checks whether the event and extrinsic in these blocks match the user-defined filter.
What happens when a dictionary IS used?
When a dictionary IS used, the indexer will first take the call and event filters as parameters and merge this into a GraphQL query. It then uses the dictionary's API to obtain a list of relevant block heights only that contains the specific events and extrinsics. Often this is substantially less than 100 if the default is used.
For example, imagine a situation where you're indexing transfer events. Not all blocks have this event (in the image below there are no transfer events in blocks 3 and 4).
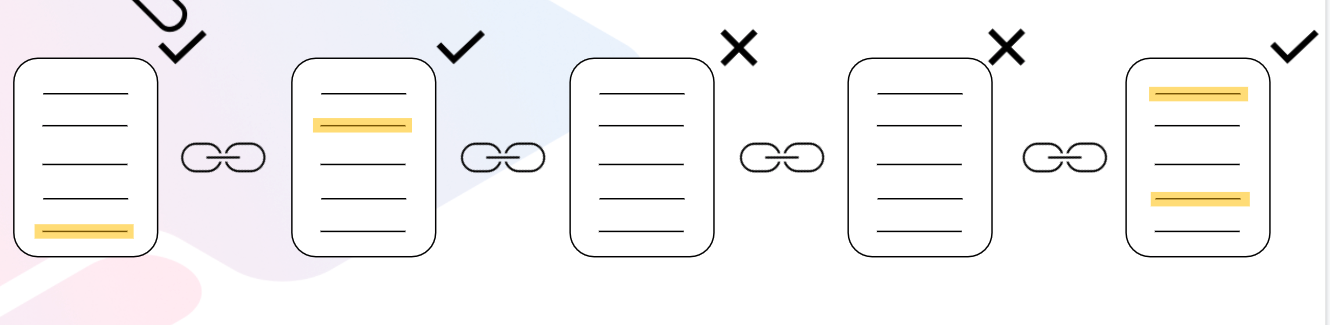
The dictionary allows your project to skip this so rather than looking in each block for a transfer event, it skips to just blocks 1, 2, and 5. This is because the dictionary is a pre-computed reference to all calls and events in each block.
This means that using a dictionary can reduce the amount of data that the indexer obtains from the chain and reduce the number of “unwanted” blocks stored in the local buffer. But compared to the traditional method, it adds an additional step to get data from the dictionary’s API.
When is a dictionary NOT useful?
When block handlers are used to grab data from a chain, every block needs to be processed. Therefore, using a dictionary in this case does not provide any advantage and the indexer will automatically switch to the default non-dictionary approach.
Also, when dealing with events or extrinsic that occur or exist in every block such as timestamp.set, using a dictionary will not offer any additional advantage.