Querying Data with BigQuery
Querying Data with BigQuery
Google BigQuery is a fully managed, server-less data warehouse provided by Google Cloud. It allows you to run super-fast, SQL-like queries against large datasets. BigQuery is particularly well-suited for analysing large volumes of data, including blockchain data, due to its scalability, speed, and ease of use. You might use BigQuery to analyse indexed SubQuery data due to:
- Scalability: BigQuery is designed to handle massive datasets, making it suitable for analysing the vast amounts of data generated by blockchain networks.
- Speed: BigQuery can process queries on large datasets quickly, allowing you to get insights from your blockchain data in near real-time.
- SQL-like Queries: BigQuery supports standard SQL queries, making it easy for analysts and developers familiar with SQL to analyse blockchain data without having to learn a new query language.
- Server less: With BigQuery, you don't need to manage any infrastructure. Google handles the infrastructure, so you can focus on analysing your data.
- Integration: BigQuery integrates seamlessly with other Google Cloud services, such as Google Cloud Storage and Google Data Studio, making it easy to ingest, store, and visualise blockchain data.
SubQuery can easily be integrated with BigQuery in only a few steps, this means that you can export indexed blockchain data directly from SubQuery to BigQuery.
Integrating SubQuery with BigQuery
At a high level, the integration of SubQuery with BigQuery works over 3 steps (each that can be automated):
- Index data using SubQuery Indexing SDK
- Export data using SubQuery's CSV export
- Automate the loading of your CSV exports into BigQuery
Export data using SubQuery's CSV export
Ensure that the indexed data is set to save in CSV files by enabling the relevant CSV flag. Upon successful configuration, CSV files will be automatically created and populated as the indexing process runs.
We suggest running your project in GCP for ease of automated integration, although you can run your SubQuery project anywhere. This means you can export your CSV's to Google Cloud Storage for automated integration.
To save the data from your Docker container to Google Cloud Storage (GCS) instead of the local disk, you can use the gsutil command-line tool within your Docker container. Here's a general approach:
Install gsutil in your Docker container. You can use the following commands in your Dockerfile to install gsutil:
RUN apt-get update && apt-get install -y \
curl \
gnupg \
&& curl https://sdk.cloud.google.com | bashThis will install the Google Cloud SDK, which includes gsutil.
Authenticate gsutil: You need to authenticate gsutil with your Google Cloud account. You can do this by running the following commands and following the instructions to authenticate:
gcloud auth loginUse gsutil to copy your CSV file to GCS. Once authenticated, you can use gsutil cp command to copy your CSV file to GCS. For example, if your CSV file is /path/to/your/local/file.csv and you want to upload it to a bucket named your-bucket:
gsutil cp /path/to/your/local/file.csv gs://your-bucket/Replace your-bucket with your actual bucket name.
Make sure to handle any permissions and access issues based on your GCP setup.
Adding CSV Data to BigQuery
Once a sufficient amount of data is indexed for analysis, it's time to load it into BigQuery. Begin by creating an account on Google Cloud if you haven't already. Follow the steps outlined in Enable the BigQuery sandbox to set up your account.
Once your account is created, you can proceed to batch load the data. Depending on your deployment setup, the commands for loading data to BigQuery may vary slightly. Refer to specific guides for more details:
Alternatively, you can use the bq command-line tool to load the CSV file into BigQuery. Here's an example command:
bq load --autodetect --source_format=CSV your_dataset.your_table gs://your-bucket/your-file.csv
Replace your_dataset with your dataset name, your_table with your table name, and gs://your-bucket/your-file.csv with the path to your CSV file in GCS.
Make sure to have the necessary permissions to create tables in BigQuery and read from GCS.
Query your data in BigQuery
After loading the data, you can proceed to query it. The provided screenshot from the Google Console showcases the successful execution of a SELECT * query on one of the loaded CSV files:
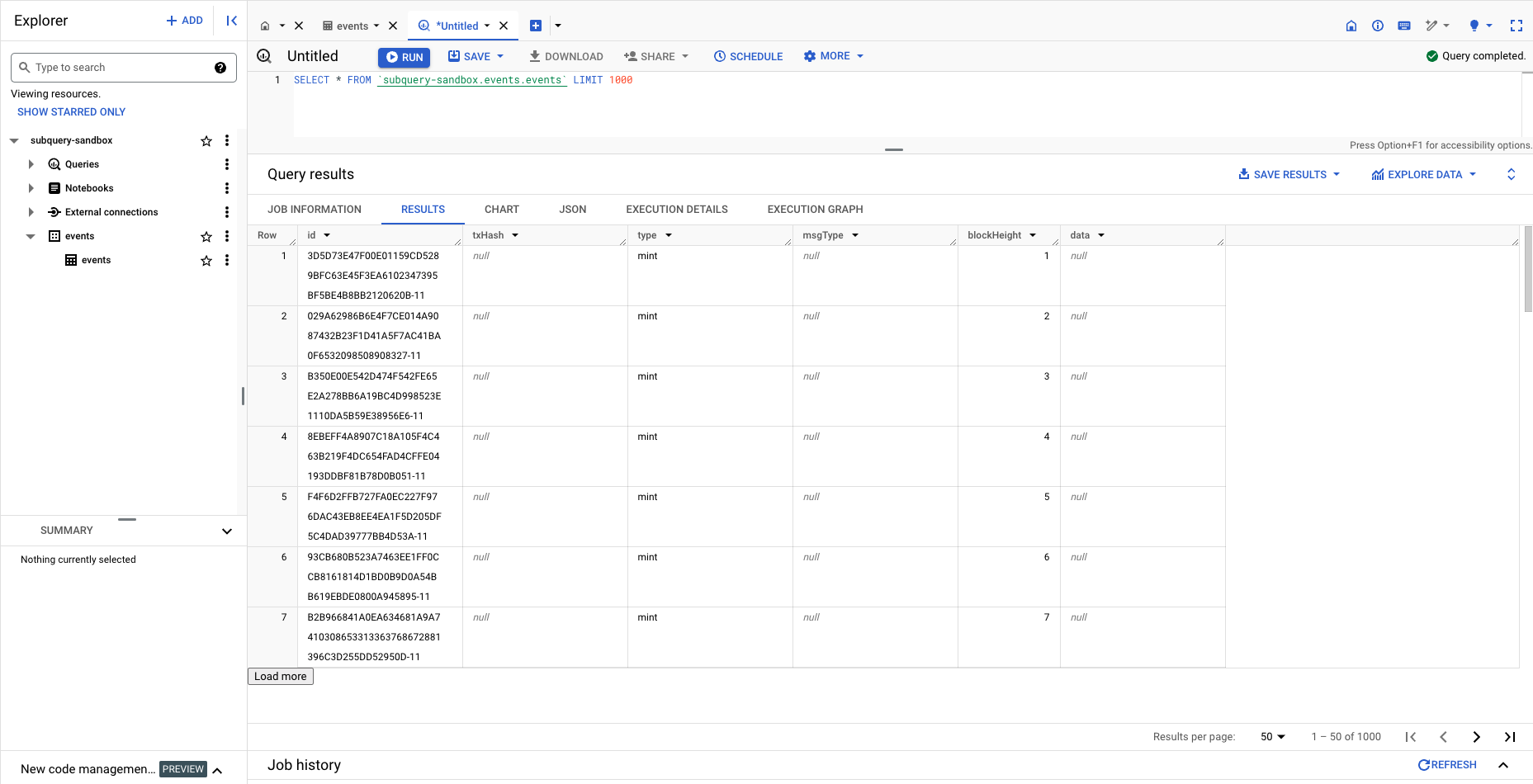
By uploading your data to BigQuery, you not only gain access to a platform designed for limitless scalability and seamless integration with Google Cloud services but also benefit from a server-less architecture. This allows you to focus on analytics rather than infrastructure management, marking a strategic move towards maximising the potential of your data.
Synchronise Updates Automatically
The act of loading a CSV file from Google Cloud Storage or a Local Disk into Google BigQuery does not establish automatic synchronisation or updates. Should you or the SubQuery Indexer make modifications to the CSV file in GCS, it becomes necessary to manually reload the updated file into BigQuery following the same procedural steps.
To streamline and automate this process, consider implementing a recurring job through Google Cloud services or configuring a cron job using the recommended commands. Alternatively, you can incorporate this automation directly within the mapping file code. For example, create a block handler with a specific modulo to load your data in batches at predetermined intervals. These services will initiate a load job in BigQuery, ensuring your data stays synchronised effortlessly.